SQL Server / Query Optimization / Merge Join Operator / Sort Operator
Posted by Barac in SQL Server on May 30th, 2018 | 0 commentsRecently we had really nice meetup gathering here in Auckland. Was a beautiful evening, there were 20 people talking about SQL server, was perfect. One of the topics was “Merge Join Operator”
For this demo I used SQL Server 2014 Developer Edition.
As a database I used StackOverflow, you can download this DB from Brent Ozar web page, just follow the instructions
How to Download the Stack Overflow Database via BitTorrent
In this example I will use two tables Badges (25 million rows) and Users (8 million rows) and I will join them on Userid (Badges) and Id (Users) columns. We have just clustered indexes on those two tables. I just want to show you one query example with Merge Join and Sort operator.
So lets try following query
We are returning 98599 rows with this query.
When we check statistics we can see that query creating so-called Worktable
(98599 row(s) affected)
Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Badges’. Scan count 1, logical reads 155202, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Users’. Scan count 1, logical reads 120104, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Reason for that is that our SQL Server thinks that when we have duplicated values in our outer table and then SQL server create so-called Worktable in the tempdb.
Lets now check the Execution Plan
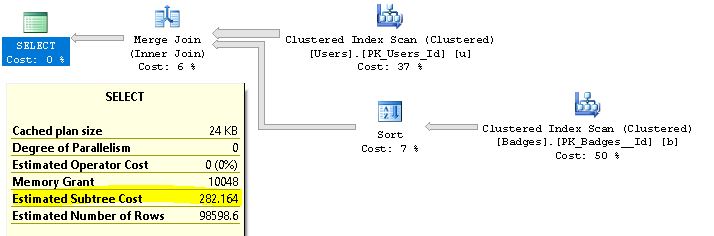
You can see here that we have Merge Join Operator in our execution plan. Query optimizer thinks that for this number of rows (this case 98599) Merge Join is the better option then using Nested Loop or Hash join operator, even if we need sort operator to perform Merge Join in this query.
Merge join needs sorted input to perform efficiently as possible. Our join columns are Badges.UserID and Users.Id

As I mentioned at the beginning of the post we do not have any indexes on tables, except clustered index.
Table Badges is sorted by clustered index PK_Badges_Id, column Id
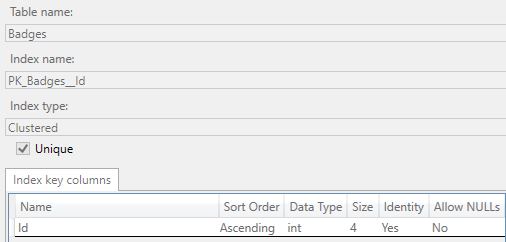
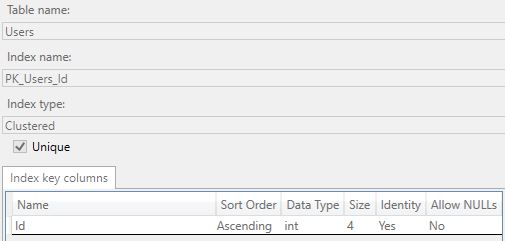
Table Users is sorted by clustered index PK_Users_Id, column Id
You noticed that we have sort operator in our execution plan. Merge join needs sorted input to perform efficiently as possible, because of that we have the sort operator on our Badges table sorted by UserId column since that is our join column.

In some cases this sort operator can be really expensive so let’s remove it from our execution plan.
To accomplish this we need to add an index which will be sorted by column we are using as a join predicate (UserID in Badges Table) and in this case we need to include column we have in the WHERE clause as well. This way we will presort the data before joining the tables.
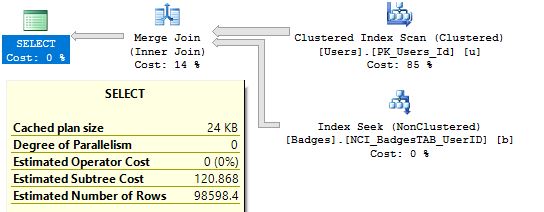
If we run this query again we will get following execution plan
(98599 row(s) affected)
Table ‘Badges’. Scan count 1, logical reads 323, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Users’. Scan count 1, logical reads 120102, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
We have an index seek on newly created Non Clustered index and at the same time we have the lower number of logical reads than in previous query (323<155202).
If we add another index on User table to remove that Clustered Index Scan.
We will get following execution plan
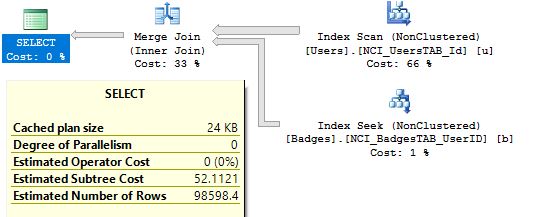
(98599 row(s) affected)
Table ‘Badges’. Scan count 1, logical reads 323, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Users’. Scan count 1, logical reads 32140, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
We still have Scan but it is Non clustered index scan, size of the index is much smaller then clustered one.
If you run following query you will get Index Size and Page Number for the particular index
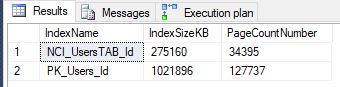
We have index scan on user table using newly created non-clustered index NCI_UsersTAB_Id. Size of the non clustered index NCI_UsersTAB_Id and page number behind it is smaller than in case using clustered index scan and for that reason index scan operation is faster, less logical reads 32000 instead of 120102.
In this example, I tried to keep my execution plan to continue using MERGE JOIN operator without forcing it. More additional explanations and examples about MERGE JOIN you can find on following MSDN article.
In one of the previous examples, we saw what bad estimates and excessive memory grant can do with our query plan. But what if we have underestimated number of rows? Here is an example.
Similar Posts:
- SQL Server / Query Optimization / String functions in the WHERE clause and bad estimates
- SQL Server / Query Optimization / TempDB Page Splits / Table Spool (Lazy Spool)
- SQL Server / Query Optimization / Memory Grant Warning / Excessive Grant
- SQL Server / Index Usage Report Project
- SQL Server / ALTER INDEX / CREATE INDEX Progress

About Me

My name is Zoran, currently living in Auckland, New Zealand. I am a data specialist with more than 15 years of hands-on experience in database administration and optimisation. I am also, Certified Microsoft Trainer (MCT) and Microsoft Certified Solutions Expert (MCSE) with a Master‘s degree in Information Technology. Sharing knowledge and contributing to the SQL Server community is my passion. I am also an organiser of the Auckland SQL User Meetup Group. As well I am active blogger and speaker at different SQL events such as SQL Saturdays, Meetups etc.
read moreAuckland SQL Group


MSDN PROFILE
 SQL SERVER UPDATES
SQL SERVER UPDATES
- Microsoft SQL Server 2022 Updates / Release Candidate (RC 1) Evaluation Edition (16.0.950.9)
- Microsoft SQL Server 2019 Updates / BETA (15.0.1000.34) / RTM (15.0.2000.5)
- Microsoft SQL Server 2017 Updates / RTM (14.0.1000.169)
- Microsoft SQL Server 2016 Updates / RTM (13.0.1601.5) / SP1 (13.0.4001.0 or 13.1.4001.0) / SP2 (13.0.5026.0 or 13.2.5026.0) / SP3 (13.0.6300.2 or 13.3.6300.2)
- Microsoft SQL Server 2014 Updates / RTM (12.0.2000.0) / SP1 (12.0.4100.1 or 12.1.4100.1) / SP2 (12.0.5000.0 or 12.2.5000.0) / SP3 (12.0.6024.0 or 12.3.6024.0)
- Microsoft SQL Server 2012 Updates / RTM (11.00.2100) / SP1 (11.0.3000.0 or 11.1.3000.0) / SP2 (11.0.5058.0 or 11.2.5058.0) / SP3 (11.0.6020.0 or 11.3.6020.0) / SP4 (11.0.7001.0 or 11.4.7001.0)
Leave a Reply