SQL Server / Availability Group / Readable Secondary Replica Delay / Parallel Redo Operations
Posted by Barac in SQL Monitoring, SQL Server, SQL Tips and Tricks on Apr 10th, 2021 | 0 commentsOne of the most common issues with Availability Group and using readable secondary replica is with Parallel REDO operations.
On your readable secondary replica, you will notice a few different types of waits commonly related to this, but in this article, I will cover just one of them PARALLEL_REDO_TRAN_TURN
PARALLEL_REDO_TRAN_TURN
This type of waits happens in readable secondary replica and it is caused by page splits or forwarded records on heap tables triggered by new inserts or updates on primary replica.

There are few ways to fix this issue
– Reduce the number of pages splits on the primary replica
– Reduce the number of forwarded records (heap tables)
– Using trace flag 3459, DBCC TRACEON (3459, -1) and disabling parallel redo
So how to monitor this?
I am using the following query:
And this is my RedoSeconds time:
With a slight adjustment, I wrap this query in form of an alert to be forwarded to my email.
Depending on your settings email may looks like following:

The last step would be to create an Agent job on the replica you want to monitor.
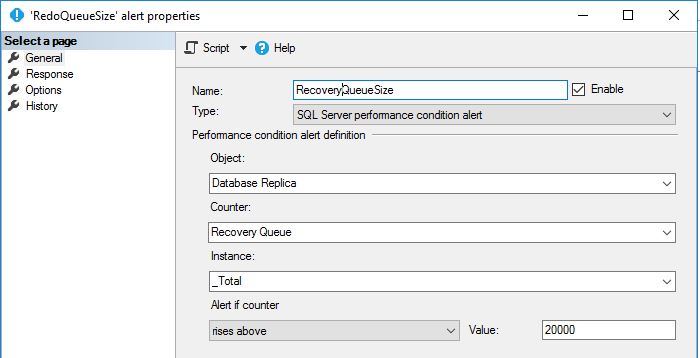
There are few counters you can use as alert to trigger this job, I am personally using:
“Recovery Queue”
Amount of log records in the log files of the secondary replica that have not been redone.
Similar Posts:
- SQL Server / DB Backup Size Last Month / Email Alert
- SQL Server / Missing Indexes Query / DMV / Email Alert
- SQL Server / Missing Indexes Query / Cached Plans / Email Alert
- SQL Server / Long Running Queries / Email Alert
- SQL Server / Configure an Azure Load Balancer for a SQL Server Always On AG in Azure Virtual Machines / Possible Floating IP and Health Probes Connectivity and Networking issues

About Me

My name is Zoran, currently living in Auckland, New Zealand. I am a data specialist with more than 15 years of hands-on experience in database administration and optimisation. I am also, Certified Microsoft Trainer (MCT) and Microsoft Certified Solutions Expert (MCSE) with a Master‘s degree in Information Technology. Sharing knowledge and contributing to the SQL Server community is my passion. I am also an organiser of the Auckland SQL User Meetup Group. As well I am active blogger and speaker at different SQL events such as SQL Saturdays, Meetups etc.
read moreAuckland SQL Group


MSDN PROFILE
 SQL SERVER UPDATES
SQL SERVER UPDATES
- Microsoft SQL Server 2022 Updates / Release Candidate (RC 1) Evaluation Edition (16.0.950.9)
- Microsoft SQL Server 2019 Updates / BETA (15.0.1000.34) / RTM (15.0.2000.5)
- Microsoft SQL Server 2017 Updates / RTM (14.0.1000.169)
- Microsoft SQL Server 2016 Updates / RTM (13.0.1601.5) / SP1 (13.0.4001.0 or 13.1.4001.0) / SP2 (13.0.5026.0 or 13.2.5026.0) / SP3 (13.0.6300.2 or 13.3.6300.2)
- Microsoft SQL Server 2014 Updates / RTM (12.0.2000.0) / SP1 (12.0.4100.1 or 12.1.4100.1) / SP2 (12.0.5000.0 or 12.2.5000.0) / SP3 (12.0.6024.0 or 12.3.6024.0)
- Microsoft SQL Server 2012 Updates / RTM (11.00.2100) / SP1 (11.0.3000.0 or 11.1.3000.0) / SP2 (11.0.5058.0 or 11.2.5058.0) / SP3 (11.0.6020.0 or 11.3.6020.0) / SP4 (11.0.7001.0 or 11.4.7001.0)
Leave a Reply